
In today’s digital age, data is a critical asset for organizations, and collecting data from various sources is essential for businesses to make informed decisions. However, the data collected is often in different formats and structures, making it challenging to analyze. To make sense of the data, it is essential to extract, transform, and load (ETL) it into a suitable format.
In recent years, near real-time streaming data has become a popular means of data collection due to its timeliness and accuracy. To process such data, an ETL pipeline is necessary. In this blog, we will discuss how to build a robust and scalable ETL pipeline for near real-time streaming data using AWS Kinesis, Kinesis Data Analytics (KDA), and Kinesis Data Streams (KDS).
ETL Pipeline Architecture:
The ETL pipeline architecture for near real-time streaming data using AWS Kinesis, KDA, and KDS comprises several components. The components are:
- Data Source: The data source can be any streaming source like IoT sensors, weblogs, social media, or any other streaming data source.
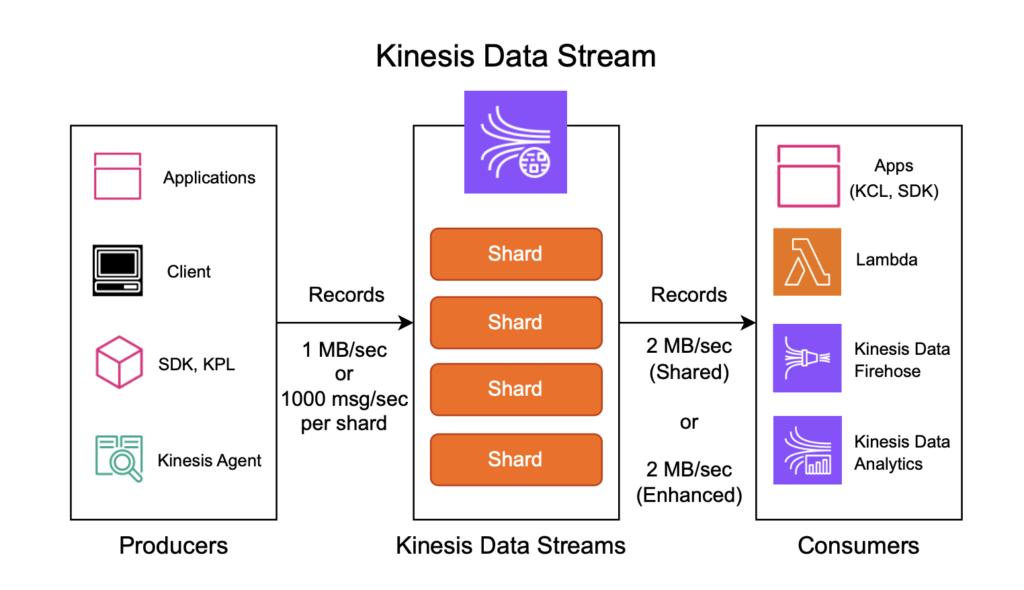
- Kinesis Data Streams (KDS): Kinesis Data Streams is a reliable and scalable real-time data streaming service that can capture and store terabytes of data per hour from multiple sources.
- Kinesis Data Analytics (KDA): Kinesis Data Analytics is a serverless service that makes it easy to analyze streaming data with SQL queries. KDA can continuously process and analyze streaming data from Kinesis Data Streams and output the results to various targets.
- Target: The target can be any suitable storage or database system that can store the transformed data, such as Amazon S3, Amazon Redshift, Amazon DynamoDB, or any other storage system.
ETL Pipeline Steps:
The ETL pipeline for near real-time streaming data using AWS Kinesis, KDA, and KDS consists of the following steps:
- Ingest Data into Kinesis Data Streams: The first step is to ingest the streaming data into Kinesis Data Streams. The data can be ingested using Kinesis Producer Library (KPL) or Kinesis Agent, which can read data from various sources and write it to Kinesis Data Streams.
- Process Data using Kinesis Data Analytics: The next step is to process the streaming data using Kinesis Data Analytics. KDA can continuously process and analyse the streaming data from Kinesis Data Streams and output the results to various targets. KDA can be configured to execute SQL queries on the incoming streaming data and transform it into a desired format.
- Load Data into Target Storage: The final step is to load the transformed data into a target storage system, such as Amazon S3, Amazon Redshift, Amazon DynamoDB, or any other storage system. This can be achieved using Kinesis Data Firehose, which is a fully managed service that can load streaming data into various targets.
Benefits of Using AWS Kinesis, KDA, and KDS:
- Scalability: AWS Kinesis, KDA, and KDS are highly scalable and can handle terabytes of data per hour from multiple sources.
- Real-time Data Processing: Kinesis Data Streams can continuously capture and store real-time streaming data, while KDA can process the streaming data in real-time.
- Serverless Architecture: Kinesis Data Analytics and Kinesis Data Firehose are serverless services, which means there is no need to manage any infrastructure.
- Easy Integration: Kinesis Data Streams, KDA, and Kinesis Data Firehose can be easily integrated with other AWS services like Amazon S3, Amazon Redshift, and Amazon DynamoDB.
Challenges of Building an ETL Pipeline:
Building an ETL pipeline for near real-time streaming data using AWS Kinesis, KDA, and KDS can be challenging due to several factors, including:
- Complexity: Building an ETL pipeline requires expertise in AWS services like Kinesis, KDA, and KDS, and SQL queries. Therefore, it can be challenging for organizations that do not have experienced AWS professionals.
- Cost: While AWS Kinesis, KDA, and KDS offer a cost-effective solution for processing near real-time streaming data, the cost can increase as the volume of data increases.
- Maintenance: ETL pipelines require continuous monitoring and maintenance to ensure they operate efficiently. This can be time-consuming, and organizations may need to allocate dedicated resources for this purpose.
Best Practices for Building an ETL Pipeline:
To build a robust and scalable ETL pipeline for near real-time streaming data using AWS Kinesis, KDA, and KDS, organizations should follow these best practices:
- Design for Scalability: When designing an ETL pipeline, organizations should consider scalability as a primary factor. The pipeline should be able to handle an increasing volume of data without impacting performance.
- Use AWS Best Practices: AWS offers a set of best practices for building ETL pipelines using Kinesis, KDA, and KDS. Organizations should follow these best practices to ensure they build a reliable and efficient ETL pipeline.
- Monitor and Optimize: ETL pipelines require continuous monitoring and optimization to ensure they operate efficiently. Organizations should use AWS CloudWatch to monitor the pipeline’s performance and optimize it as required.
Conclusion:
Building an ETL pipeline for near real-time streaming data using AWS Kinesis, KDA, and KDS can provide organizations with a reliable and scalable solution for processing streaming data. However, building an ETL pipeline requires expertise in AWS services like Kinesis, KDA, and KDS, and SQL queries. Organizations should follow best practices for designing, monitoring, and optimizing ETL pipelines to ensure they operate efficiently. With the right approach, organizations can leverage near real-time streaming data to make informed decisions and gain a competitive advantage in their industry.