
Duplicate data is the most prevalent data quality issue that can plague a company’s database. Duplicates can originate from various sources, including user errors, import and export mistakes, and even administrator errors. Let’s explore how duplicate data can be a problem for businesses of all sizes.
What is duplicate data?
Two or more records representing the same person or object are stored in the same source system. Businesses should consider removing duplicate records from their Databases because due to the following problems.
- Slow and inefficient processes and workflows
- Unnecessary Data Storage
- Undermines data-driven decisions.
- Negative Targeting Implications
- Ineffective Customer Service.
In this blog, we will be looking at how we can remove duplicate data using AWS GLUE. Before we get our hands dirty let’s first outline the Glue objects and some additional AWS services that we will be utilizing throughout the project.
AWS GLUE:
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
- GLUE Data Catalog:
The AWS Glue Data Catalog contains references to data that is used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue.
- GLUE Crawler:
You can use a crawler to populate the AWS Glue Data Catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run.
- GLUE ETL:
Glue uses ETL (Extract, transform, load) jobs to extract data from a combination of other cloud services offered by Amazon Web Services (AWS).
- GLUE Workflow:
In AWS Glue, you can use workflows to create and visualize complex extract, transform, and load (ETL) activities involving multiple crawlers, jobs, and triggers. Each workflow manages the execution and monitoring of all its jobs and crawlers.
Note: We will be using workflow to automate our ETL process.
AWS S3:
Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps.
AWS Athena:
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Solution overview
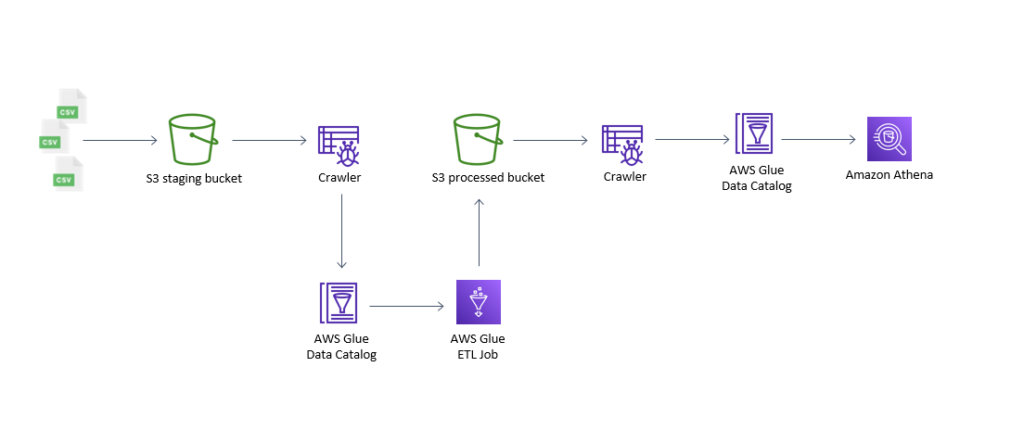
Our project entails the following high-level steps:
- A Crawler pointing to the staging bucket (s3 bucket) will crawl and populate the Data Catalog.
- GLUE ETL Job will deduplicate data from Data Catalog and save it into the S3 bucket in Parquet format.
- A subsequent crawler will crawl the processed bucket and will populate the Data Catalog.
- The data will be queried using AWS Athena to ensure the deduplication.
*Step 1-3 will be automated using AWS Glue Workflow
Why Parquet file when we have other file formats available such as CSV?
- Apache Parquet is column-oriented and designed to provide efficient columnar storage compared to row-based file types such as CSV.
- It generates lower storage costs for data files and maximizes the effectiveness of data queries with current cloud technologies such as Amazon Athena, Redshift Spectrum, BigQuery, and Azure Data Lakes.
- Apache Parquet is designed to support very efficient compression and encoding schemes.
Creating Crawlers:
We can create a crawler using this tutorial provided by AWS.
The first crawler (Crawl-Staging-S3Bucket) that we create will
- Point to the S3 Staging bucket
- Crawl all subfolders options enabled
- Pointing to the table that will be used by GLUE ETL for processing
The subsequent crawler(Crawl-Processed-S3Bucket) that we create will
- Point to the S3 Processed bucket
- Crawl all subfolders options enabled
- Pointing to the table that will be used by GLUE ETL for processing.
Creating Glue Job:
This link by AWS provides complete information about creating ETL jobs using AWS Glue studio. For ease, we can use “Visual with a source and target” and later on edit the script to perform the steps the visualizer doesn’t offer.
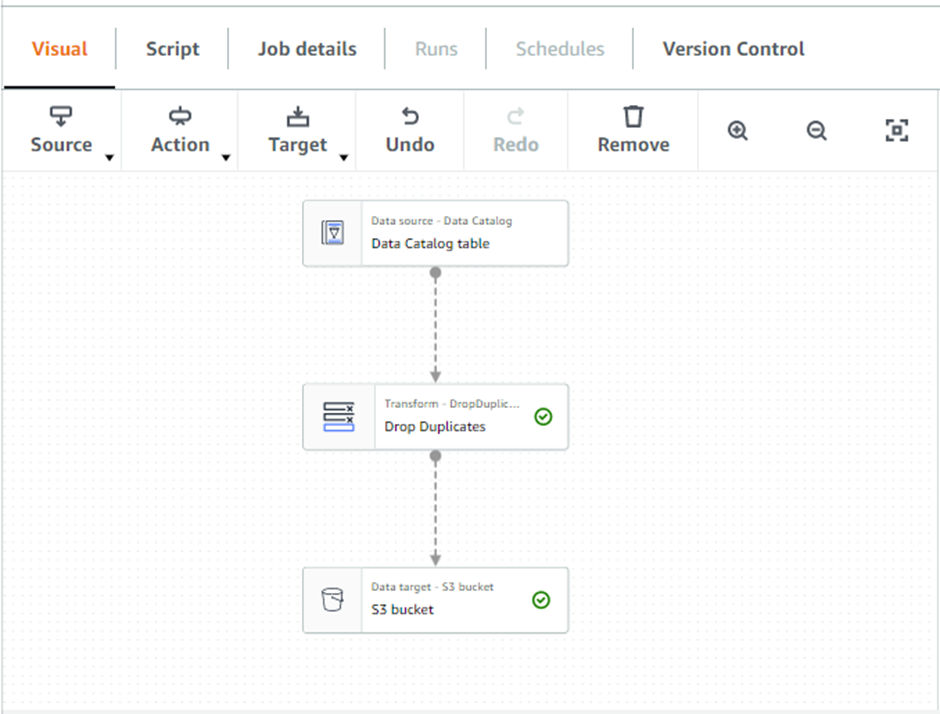
Configuring the Nodes:
Data Source:
Select the database table (already created by the first crawler) from the node properties
Transformation:
Select the node type from the properties and replace the default transformation (apply mapping) to drop duplicates)
Data Target:
Navigate to the Data properties and select Parquet format in the output data format. In the S3 Target, location specify the S3 Processed Bucket (will store the parquet files)
Creating Glue Workflow:
To automate the first three steps, we need to create AWS Workflow, the workflow we create for the above steps will have the following graph:
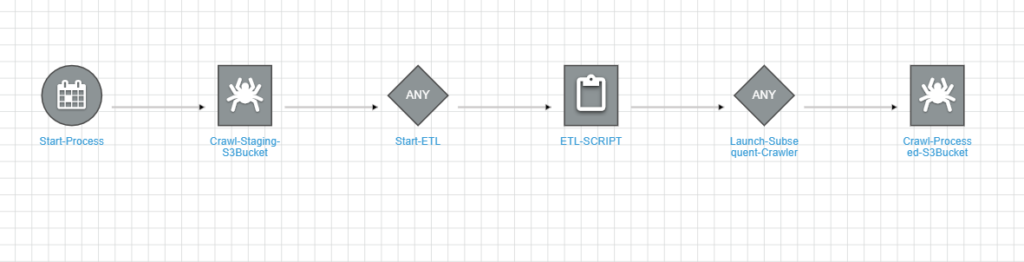
Aws workflow will have the following triggers:
Start-Process Trigger:
This scheduled trigger will trigger the first crawler (Crawl-Staging-S3Bucket) to populate the glue Data Catalog.
Start-ETL Trigger
This Trigger will watch the completion of the first crawler and upon completion will start the
Glue Job (ETL-SCRIPT in this case).
Launch-Subsequent-Crawler Trigger:
This trigger will watch the ETL to complete and upon completion will trigger the crawler (Crawl-Process-S3Bucket)
Note: AWS GLUE Workflow can run manually or through the Amazon EventBridge event.
Verifying deduplication using Amazon Athena:
After the GLUE ETL job completes and the Data Catalog gets populated, we can use AWS Athena to query the table and verify if the duplicates we wanted to remove have been removed. Follow the following steps:
- Navigate to the AWS Athena Query Editor.
- Select the database and table populated using Crawl-Processed-S3Bucket.
- Use an SQL query to verify the results.
Cost Estimation for the solution:
We will estimate the cost of the solution based on the time each service takes
GLUE:
Suppose that crawlers run for 30 minutes each with the ETL job taking 2 hours.
Crawlers:
2 crawlers x 0.50 hours x 0.44 USD per DPU-hour = 0.44 USD
ETL Job:
Max (1 hour, 0.0166 hours (minimum billable duration)) = 1.00 hours (billable duration)
10 DPUs x 1.00 hours x 0.44 USD per DPU-Hour = 4.40 USD (Apache Spark ETL job cost)
Athena:
Suppose we are performing 5 queries each, with 1 GB of data scanned per query.
Total number of queries: 5 per day * (730 hours in a month / 24 hours in a day) = 152.08 queries per month
Data amount scanned per query: 1 GB x 0.0009765625 TB in a GB = 0.0009765625 TB
Rounding (152.08) = 152 Rounded total number of queries
152 queries per month x 0.0009765625 TB x 5.00 USD = 0.74USD
Total = 4.84+0.74 = 5.58 USD
The estimated cost of our project is $5.58.
Link to AWS Glue Pricing.